The vast, silent expanse of the Sahara Desert, under a sky unblemished by urban glow, has long been a canvas for contemplation, a place where the ancient astronomers of North Africa charted the heavens. Today, a new generation of Algerian innovators, armed with the formidable power of multimodal artificial intelligence, is continuing this tradition, not with astrolabes and quadrants, but with algorithms and neural networks. We are not merely looking at the stars anymore; we are listening to their echoes, watching their subtle dances, and understanding their complex narratives through the lens of AI.
The challenge of space exploration, particularly in remote sensing and astronomical observation, generates an almost unfathomable deluge of data. Think of the sheer volume of information streaming from satellites like Alcomsat-1, Algeria's first communication satellite, or the intricate signals from deep-space probes. This data arrives in disparate forms: high-resolution imagery, spectral readings, radio wave patterns, and even subtle vibrational data. To make sense of this cosmic symphony, a singular intelligence is required, one capable of perceiving and interpreting across multiple sensory modalities simultaneously. This is the domain of multimodal AI, a technological marvel that I will endeavor to make as clear as the desert sky on a moonless night.
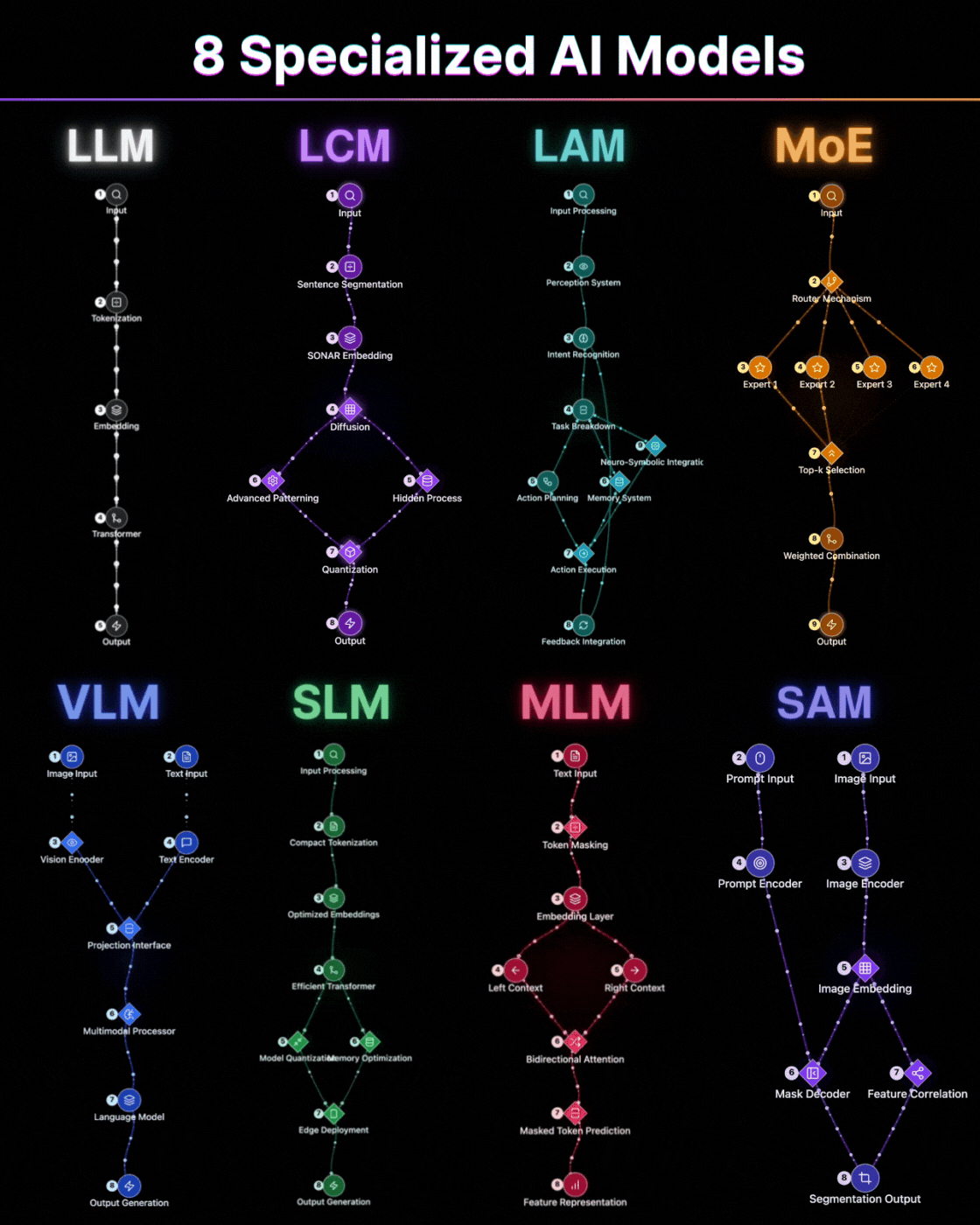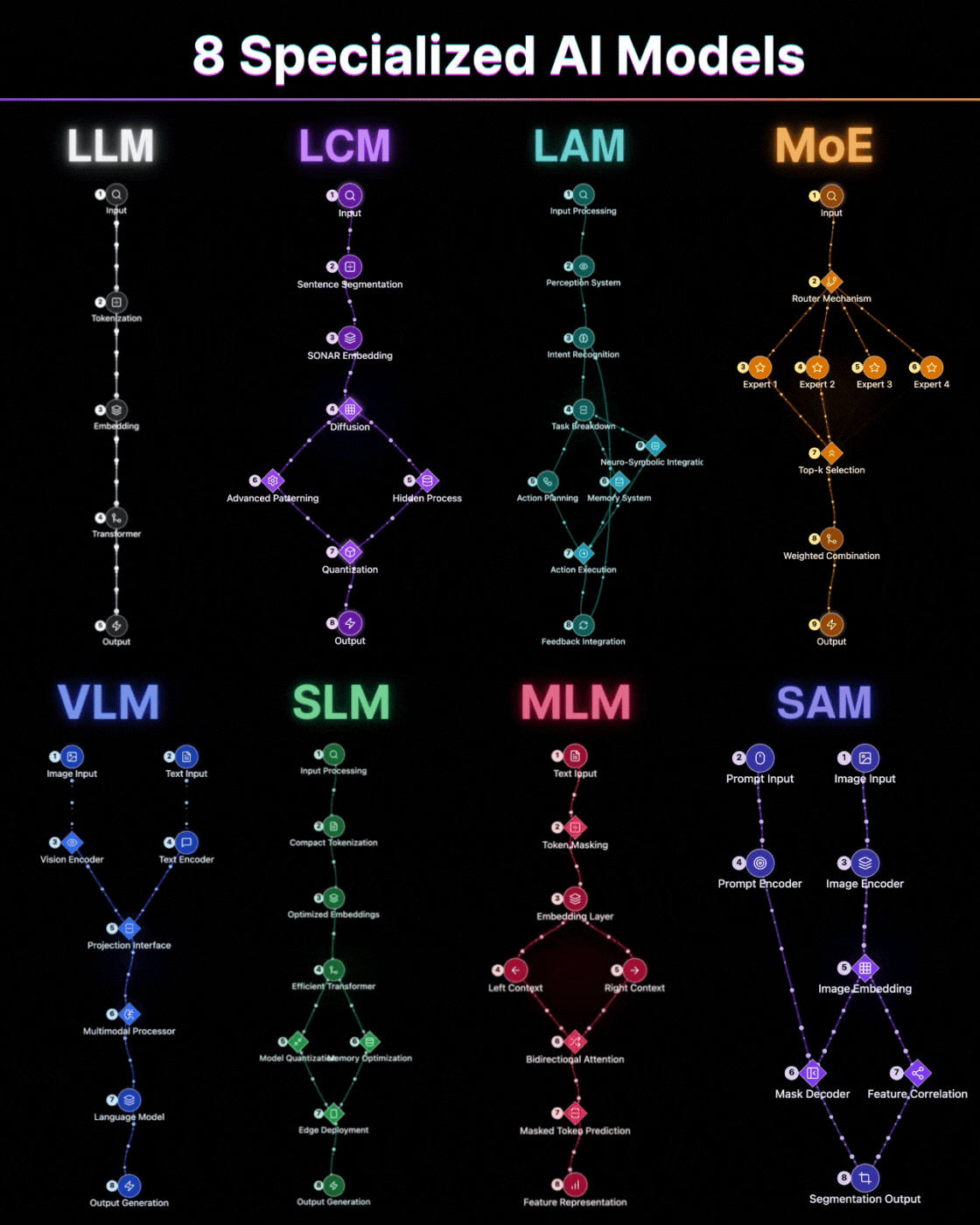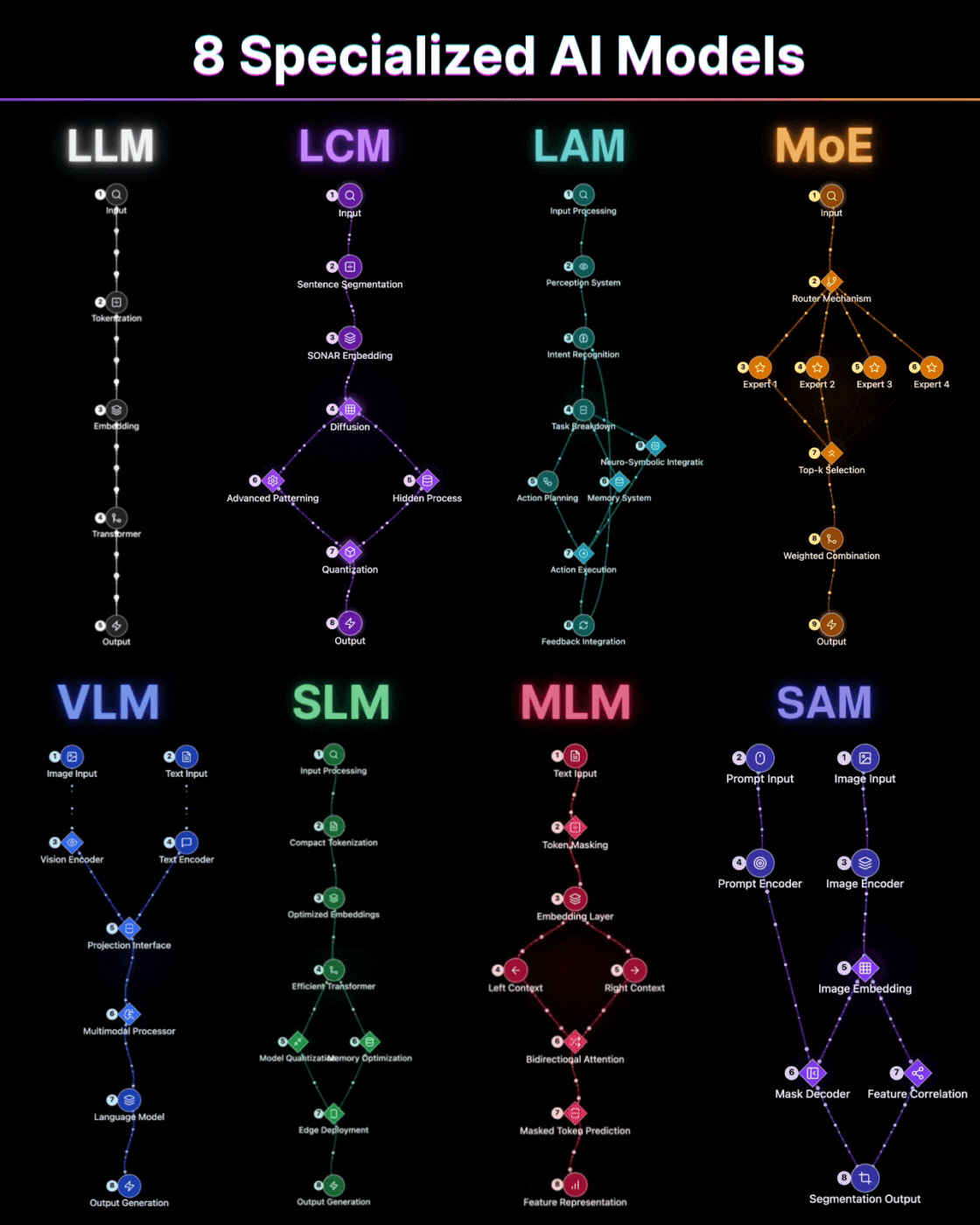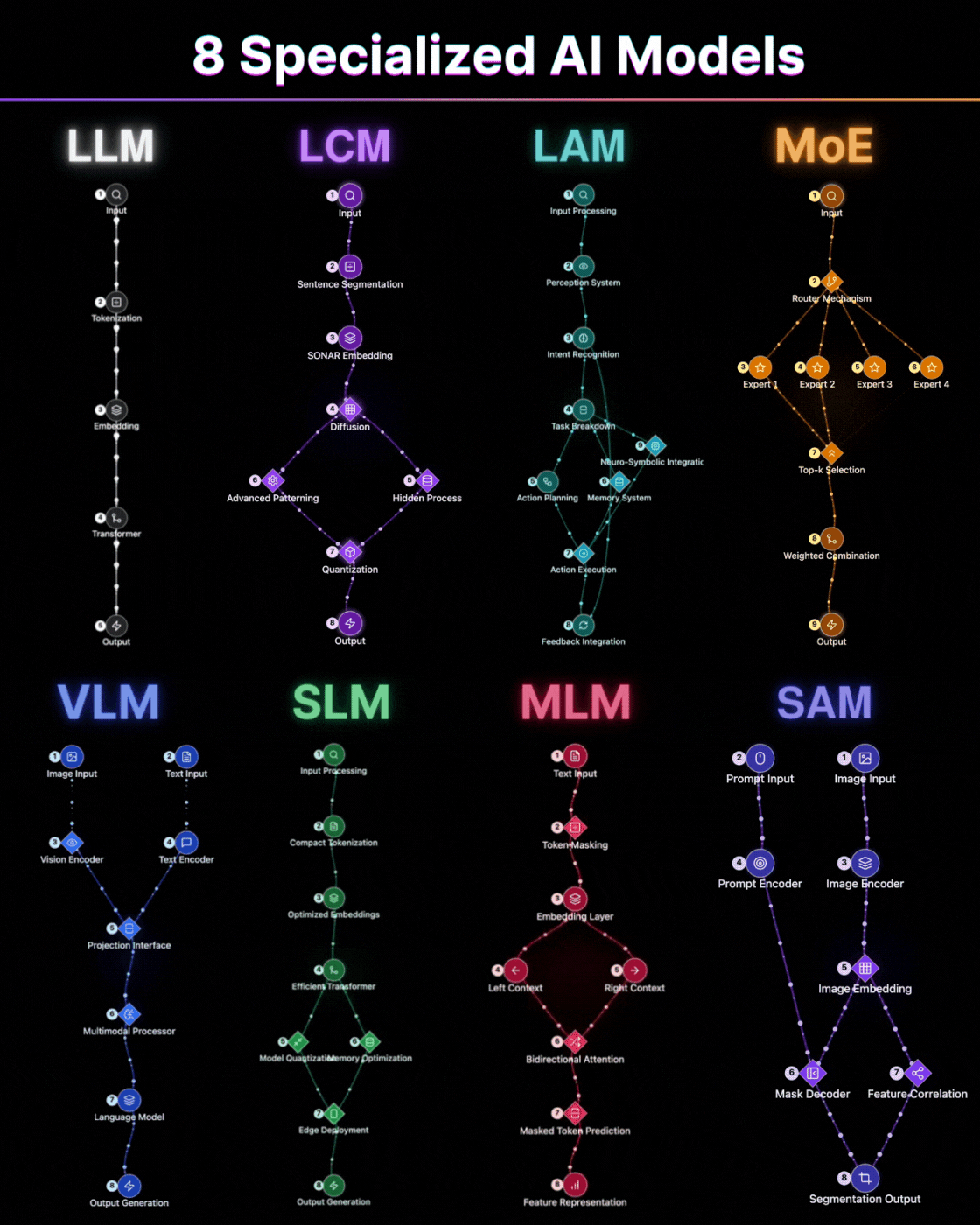
The Big Picture: What Does This System Do?
At its core, multimodal AI for space applications acts as a super-sensory interpreter. Imagine a human observer in a control room, but with dozens of eyes, ears, and specialized sensors, all operating at superhuman speeds and precision. This AI system takes in raw data streams from various sensors, optical telescopes, radio observatories, spectrometers, magnetometers, and integrates them to form a comprehensive understanding of a celestial phenomenon or a terrestrial observation from orbit. Its purpose is to detect anomalies, classify objects, predict events, and ultimately, extract actionable insights from data that would otherwise overwhelm human analysts. For instance, detecting subtle changes in planetary atmospheres, identifying new cosmic events, or monitoring environmental shifts on Earth from space are all within its purview.
The Building Blocks: Key Components Explained Simply
Let me walk you through the architecture. The elegance of these systems lies in their modularity, much like the intricate patterns of a mosaic where each piece contributes to the grand design. From a technical standpoint, a typical multimodal AI system for space comprises several key components:
-
Data Ingestion Modules: These are the gateways, responsible for receiving and preprocessing raw data from various sources. This includes image data (from visible light to infrared), audio data (radio signals, plasma wave emissions), and video feeds (time-series imagery). Each modality requires specialized handling to clean, normalize, and format the data for subsequent processing. For example, satellite imagery might undergo atmospheric correction, while radio signals are filtered for noise.
-
Modality-Specific Encoders: This is where the raw data begins its transformation into a language the AI can understand. Each data type, vision, audio, video, is fed into its own specialized neural network encoder. For visual data, this might be a Convolutional Neural Network (CNN) adept at extracting features like shapes, textures, and patterns. For audio, a Recurrent Neural Network (RNN) or a Transformer might analyze temporal sequences and frequencies. Video, being a sequence of images, often uses a combination of CNNs for spatial features and RNNs or Transformers for temporal dynamics. The output of these encoders is a high-dimensional numerical representation, a vector, capturing the essential information of that specific modality.
-
Fusion Layer: This is arguably the most critical component, the crucible where disparate sensory inputs are combined. Imagine multiple streams flowing into a single, powerful river. The fusion layer takes the encoded vectors from each modality and merges them. This can happen at different stages: early fusion (concatenating raw features), late fusion (combining predictions from separate models), or intermediate fusion (merging representations at various layers of the network). The goal is to learn joint representations that capture inter-modal relationships, for example, how a specific visual pattern correlates with a unique radio signature.
-
Decision and Output Layer: The fused representation is then passed to a final neural network layer, often a classifier or a regressor, which makes predictions or generates insights. This could be classifying a celestial object, detecting an anomaly, or even generating a textual description of an observed event.
Step by Step: How It Works From Input to Output
Consider a scenario where the Algerian Space Agency (asal) is monitoring a specific region of the Earth for environmental changes, using a combination of optical imagery, thermal imaging, and synthetic aperture radar (SAR) data from Alcomsat-1. This is a classic multimodal problem.
- Input Acquisition: Optical images capture visible light, revealing land cover and vegetation. Thermal images detect heat signatures, indicating temperature changes. SAR data penetrates clouds and provides surface structure information, even at night.
- Individual Encoding: Each data stream is fed into its respective encoder. The optical image goes through a CNN to identify patterns of deforestation or urbanization. The thermal image is processed to detect abnormal temperature gradients. The SAR data is analyzed for changes in surface roughness or moisture content.
- Feature Extraction: Each encoder outputs a compact vector, a numerical fingerprint, representing the key features of that specific modality. These vectors are rich in information but are still distinct.
- Cross-Modal Fusion: These distinct vectors are then brought together in the fusion layer. Here, the AI learns to correlate, for example, a decrease in vegetation (optical) with an increase in surface temperature (thermal) and a change in surface texture (SAR). It builds a holistic understanding that no single modality could provide alone. This is where the system truly shines, understanding the interplay between different types of evidence.
- Interpretation and Output: Finally, the fused representation is used to generate an output. This could be an alert about significant environmental degradation, a detailed map highlighting affected areas, or a prediction of future changes. The system might classify the observed event as 'desertification progression' with a confidence score of 95%, for instance.
A Worked Example: Detecting Cosmic Anomalies
Let us imagine our multimodal AI, affectionately nicknamed 'Al-Biruni' after the polymath of the Islamic Golden Age, is tasked with identifying transient astronomical events. Al-Biruni receives data from an array of ground-based radio telescopes, orbiting X-ray observatories, and Earth-based optical telescopes. A sudden burst of radio waves is detected. Simultaneously, an X-ray flare is observed in the same celestial region, followed by a faint, rapidly fading optical signature.
Al-Biruni's audio encoder processes the radio burst, identifying its unique frequency and temporal characteristics. The vision encoder analyzes the X-ray data, pinpointing the exact location and intensity of the flare. The video encoder tracks the optical signature, noting its rapid appearance and disappearance. The fusion layer then integrates these three distinct pieces of evidence. It recognizes that a specific combination of these signals, a radio burst followed by an X-ray flare and a transient optical event, strongly correlates with a known phenomenon, perhaps a gamma-ray burst or a supernova. Without multimodal integration, a human might miss the subtle connections between these disparate signals, or it would take days of painstaking analysis. Al-Biruni can do this in milliseconds, triggering immediate alerts to astronomers at the Centre de Recherche en Astronomie, Astrophysique et Géophysique (craag) near Algiers.
Why It Sometimes Fails: Limitations and Edge Cases
Despite their sophistication, these systems are not infallible. One primary limitation is the quality and quantity of training data. Multimodal AI requires vast datasets where different modalities are perfectly aligned and labeled. If the training data is scarce, biased, or poorly synchronized, the model's performance will suffer. Imagine trying to learn a language from fragmented sentences; the understanding will be incomplete. Dr. Lamine Cherif, Head of AI Research at Asal, recently noted, "Our biggest hurdle is not the algorithms themselves, but the meticulous curation of perfectly synchronized, diverse, and clean multimodal datasets. It is a monumental task, but one we are committed to." According to MIT Technology Review, data scarcity remains a significant bottleneck for advanced AI applications globally.
Another challenge is modality imbalance. If one modality provides significantly richer or more reliable information than others, the AI might inadvertently over-rely on it, neglecting valuable insights from weaker modalities. This is akin to listening intently to a loud speaker while ignoring a soft, but crucial, whisper. Furthermore, interpretability remains a concern. When Al-Biruni identifies a cosmic anomaly, understanding why it made that specific classification can be difficult, as the decision-making process within deep neural networks is often opaque. This 'black box' problem is a subject of intense research, particularly for high-stakes applications like space exploration.
Where This Is Heading: Future Improvements
The trajectory for multimodal AI in space is one of increasing sophistication and autonomy. We are moving towards more adaptive fusion techniques that can dynamically weight the importance of different modalities based on context or data quality. Imagine an AI that knows to prioritize SAR data during cloudy conditions, or optical data when atmospheric conditions are pristine. The development of self-supervised and weakly supervised learning methods will also reduce the reliance on painstakingly labeled datasets, allowing AI to learn from vast amounts of unlabeled multimodal data, much like a child learns about the world through observation rather than explicit instruction. This will be crucial for exploring truly unknown phenomena.
Furthermore, the integration of causal inference into multimodal models promises to move beyond mere correlation to understanding true cause-and-effect relationships, a leap that could revolutionize our predictive capabilities for celestial events. The mathematics behind this is elegant, drawing inspiration from probabilistic graphical models and advanced statistical mechanics. As Dr. Fatima Zahra Belkacem, a lead researcher at the University of Science and Technology Houari Boumediene, stated, "The next frontier is not just pattern recognition, but understanding the underlying mechanisms. We are building AI that can ask 'why' and 'how', not just 'what'." This aligns with global trends in AI research, with companies like DeepMind pushing boundaries in understanding complex systems.
From the ancient observatories of Timgad to the modern data centers of Algiers, Algeria's journey with the cosmos continues. Multimodal AI is not just a tool; it is an extension of our senses, allowing us to perceive the universe in ways previously unimaginable. It promises to unlock secrets hidden in plain sight, or rather, in plain sound and light, guiding our understanding of the universe and our place within it. The stars, once silent witnesses, are now speaking to us in a chorus of data, and with multimodal AI, we are finally learning to listen. This technological leap is not just about scientific discovery; it is about reinforcing our connection to a universe that has always captivated the Algerian spirit. There is an article on Lagos Just Unleashed the 'Digital Vigilante': How Edge AI is Fighting Environmental Crime, One Device at a Time [blocked] that touches upon similar themes of AI's role in environmental monitoring, albeit from a different geographical and technological perspective.