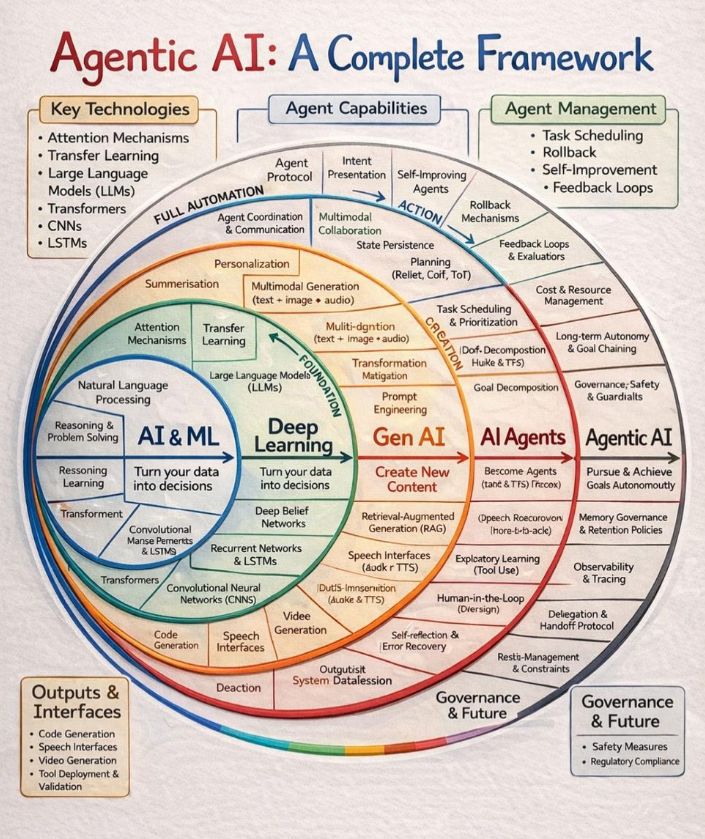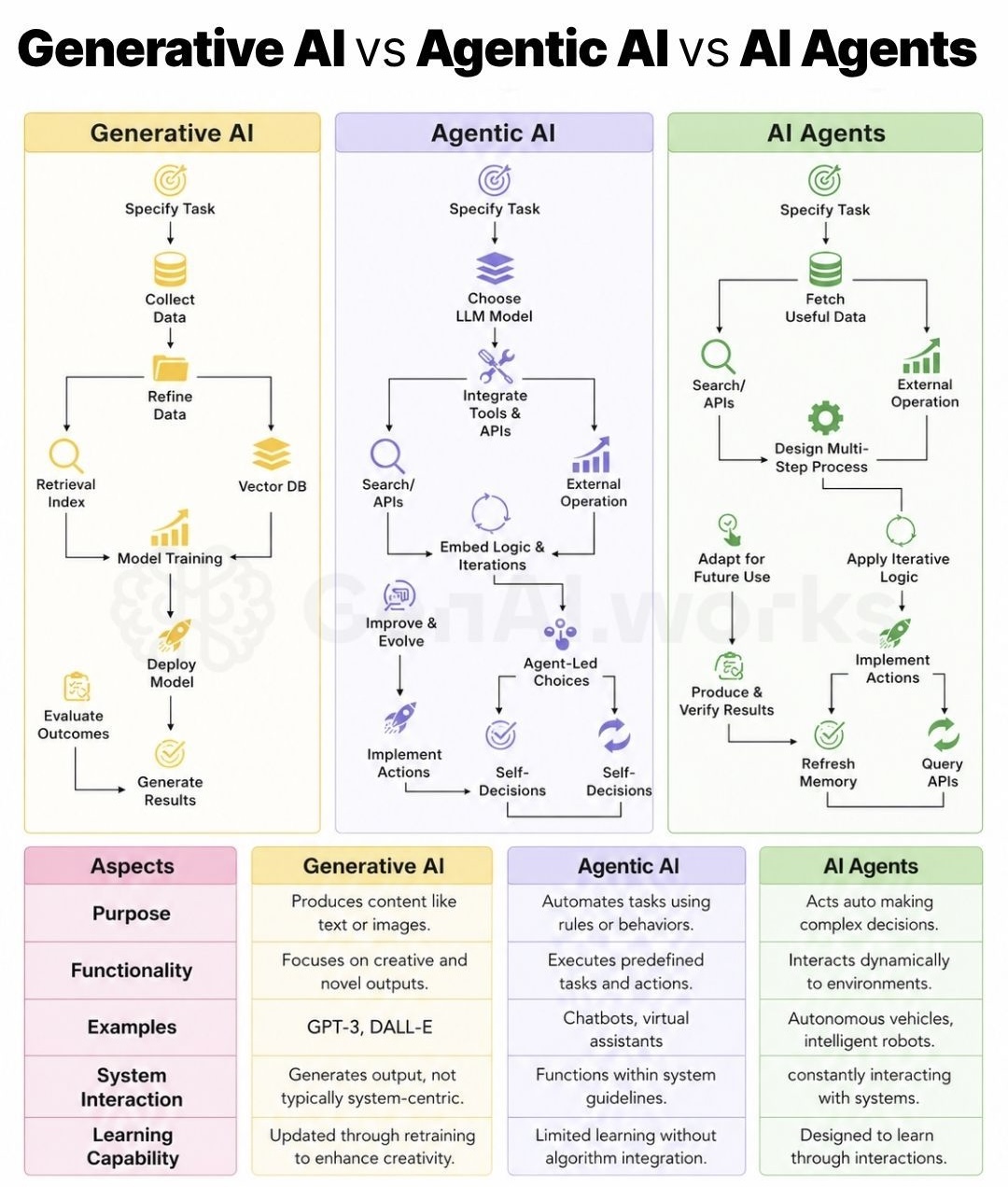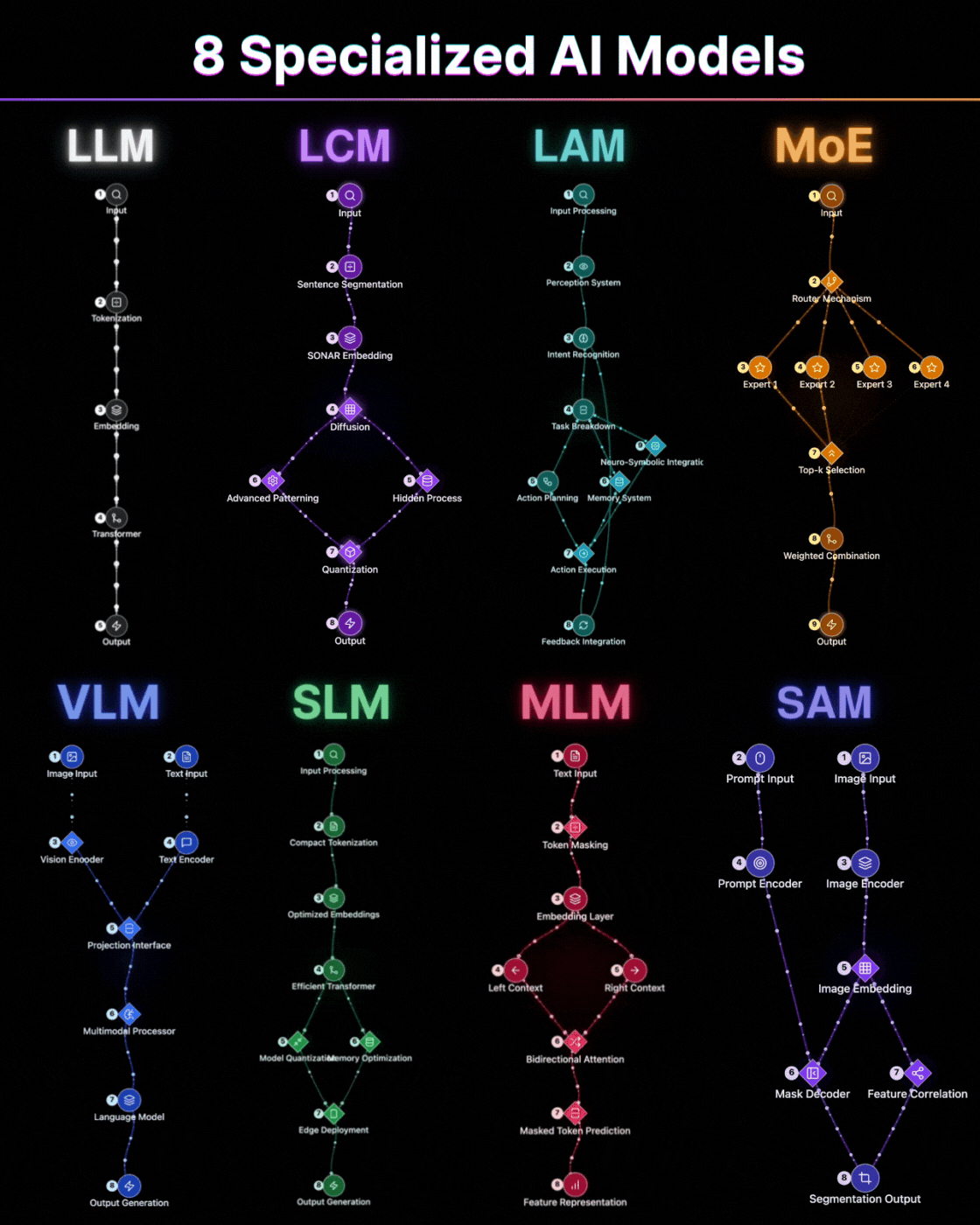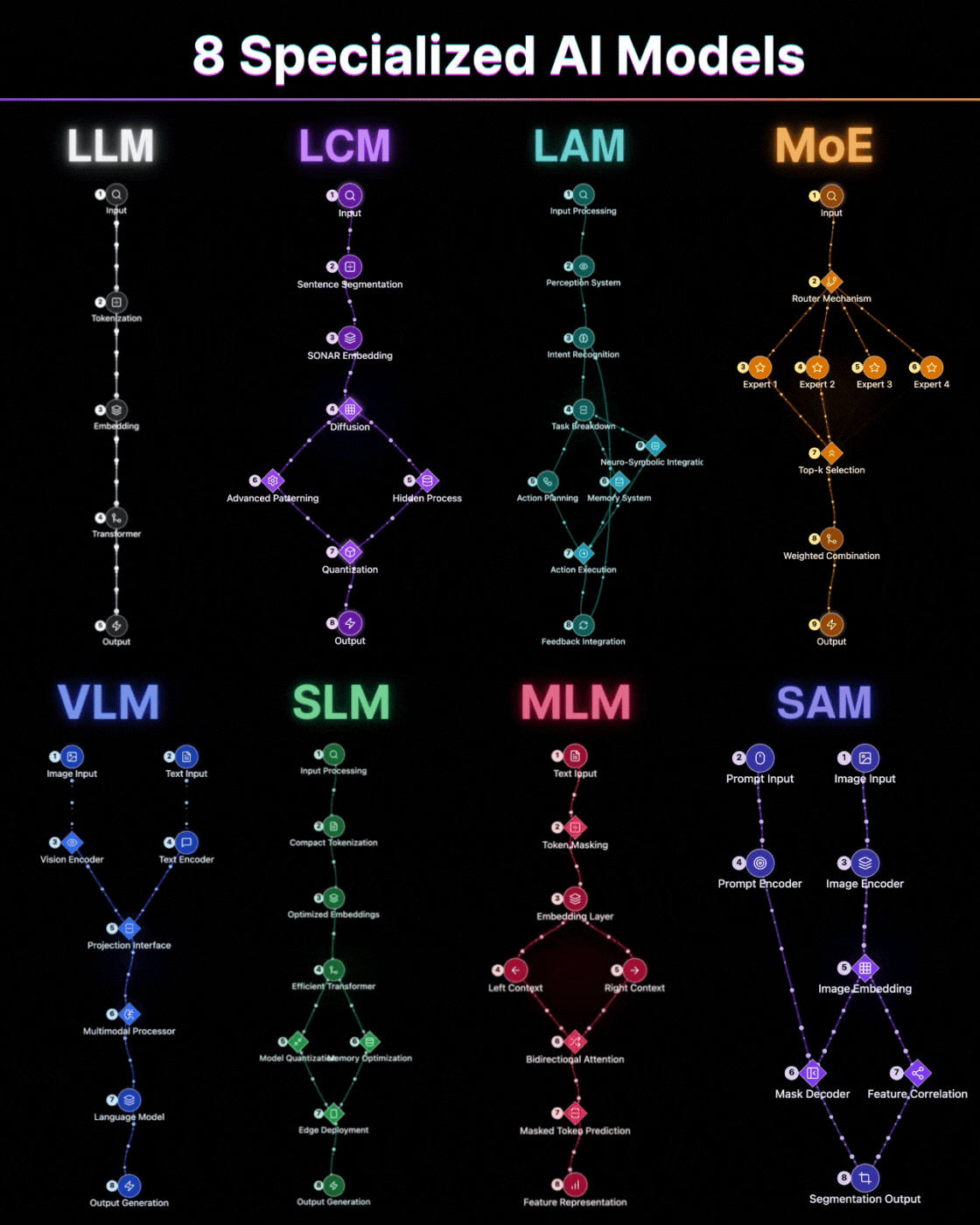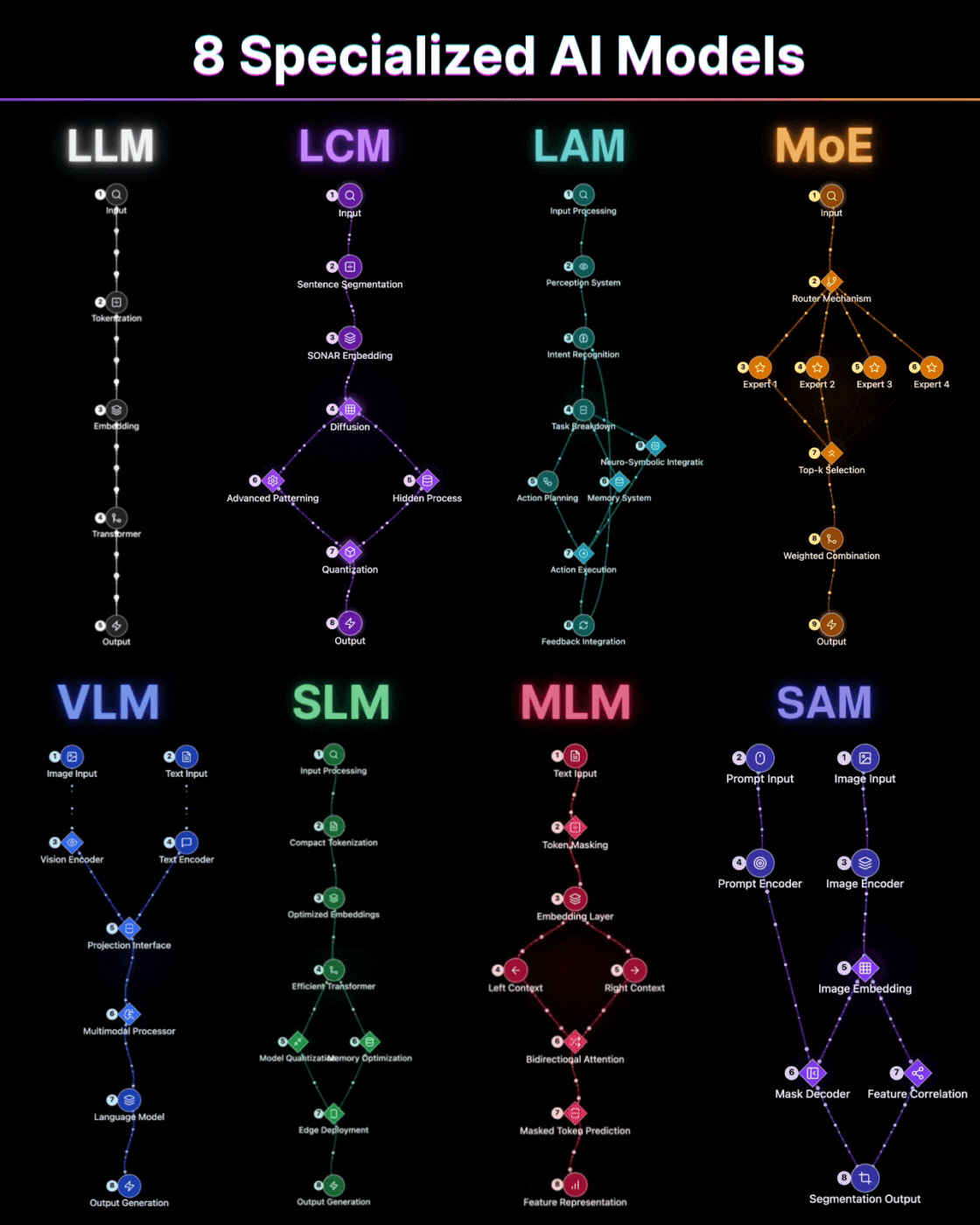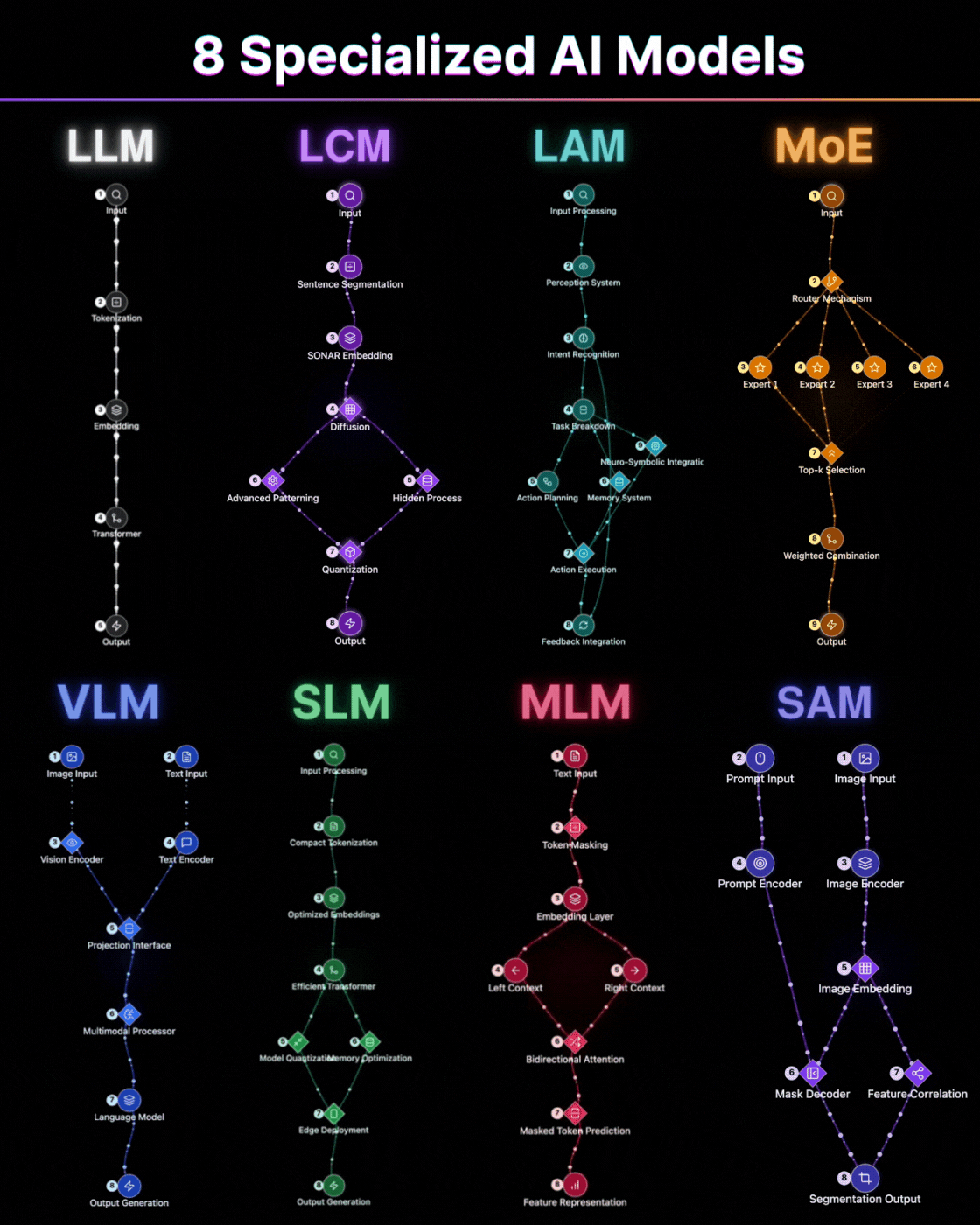

Most people think choosing an AI model means picking between "good" and "better."
The real decision is far more specific than that.
I have been watching teams burn compute, time, and budget forcing a single architecture to do everything. An LLM asked to segment pixels. A vision model asked to reason through a five-step workflow. A massive general model deployed on a device with 4GB of RAM. Every one of those choices was expensive, and not just financially. The downstream cost shows up in latency, in user experience, in the quiet erosion of trust when a product almost works but never quite delivers.
Here is what actually changed my thinking: the moment I realized that architecture is not a quality setting. It is a design decision. And like every design decision, it has consequences that compound over time.
LLM: The Sequential Thinker
Take the Large Language Model. It reads left to right, predicts the next token, and builds meaning sequentially. This is not a limitation. It is a deliberate architectural choice that makes it exceptional at generation, at continuation, at maintaining coherent long-form output. The transformer backbone processes input through tokenization, embedding, and self-attention layers that allow it to hold context across thousands of tokens. But ask it to understand an entire document simultaneously, to weigh the beginning and end with equal importance in a single pass, and you are working against the grain of what it was built to do.
MLM: The Bidirectional Reader
An MLM like BERT reads the entire sentence at once, masks tokens, and reconstructs meaning from both directions simultaneously. Neither architecture is superior. They solve fundamentally different problems. The MLM's bidirectional attention means it builds representations that account for both left and right context at every position. That makes it extraordinary for classification, for sentiment analysis, for any task where understanding matters more than generation. Using one where the other belongs is not a small inefficiency. It is a category error.
MoE: The Intelligent Router
The same logic applies across the stack. Mixture of Experts models do not process every query through every parameter. They route. A gating mechanism decides which expert sub-network is relevant and activates only that slice of the model. The result is a system that can hold the capacity of a massive model while spending the compute of a much smaller one. That is not a trick. That is architecture doing what good engineering is supposed to do: delivering maximum capability at minimum cost. The top-k selection ensures that only the most relevant experts contribute to any given input, and the weighted combination of their outputs produces results that rival dense models at a fraction of the inference cost.
LCM: The Concept Engine
Large Concept Models take this further in a direction most people have not caught up to yet. Instead of encoding words, they encode entire sentences as concept vectors in a shared semantic space through SONAR embedding. The implication is profound: the model operates at the level of meaning, not syntax. Language becomes almost incidental. The diffusion process and advanced patterning allow it to work with ideas as atomic units rather than tokens. That shift matters enormously for multilingual systems and for anything requiring genuine conceptual reasoning rather than pattern completion. When your model thinks in concepts rather than characters, translation becomes trivial and reasoning becomes natural.
SAM: The Universal Segmenter
And then there is SAM, which I think is the most underappreciated architecture in this group. Universal segmentation at pixel level, driven by a prompt. The same model that segments a medical scan can segment a satellite image or a product photo. The generalization is not accidental. It is the result of training on a dataset so diverse that the model learned the concept of a boundary rather than the appearance of any specific one. The dual-encoder architecture, with separate prompt and image encoders feeding into a shared embedding space, means it can accept any combination of point prompts, box prompts, or text prompts and produce pixel-perfect masks. The mask decoder and feature correlation work together to produce segmentation outputs that transfer across domains without fine-tuning.
LAM: The Action Orchestrator
Large Action Models represent something qualitatively different from the others on this list. They do not just process information. They act on it. The perception system feeds into intent recognition, which triggers task breakdown through neuro-symbolic integration. The action planning module coordinates with a memory system to execute multi-step workflows with feedback integration at every stage. This is not a language model with tools bolted on. It is an architecture designed from the ground up to close the loop between understanding and execution. The implications for autonomous agents and workflow automation are difficult to overstate.
VLM: The Multimodal Bridge
Vision Language Models solve a problem that neither pure vision models nor pure language models can address alone: the alignment between visual and textual understanding. The projection interface between the vision encoder and text encoder creates a shared representational space where an image and its description occupy the same geometric neighborhood. The multimodal processor then reasons across both modalities simultaneously. This is not image captioning. This is genuine cross-modal understanding, where the model can answer questions about images, generate images from descriptions, and reason about visual scenes using linguistic concepts.
SLM: The Edge Specialist
Small Language Models deserve more respect than they typically receive. The architecture is not simply a smaller version of an LLM. It is a fundamentally different engineering exercise. Compact tokenization, optimized embeddings, efficient transformer variants, aggressive model quantization, and memory optimization all work together to produce a model that runs on edge devices with meaningful capability. The constraint is the point. When you cannot afford to send every query to a cloud endpoint, when latency matters more than marginal accuracy, when privacy requirements demand local processing, the SLM is not a compromise. It is the correct architectural choice.
The Matching Problem
The honest truth is that most AI failures I have seen were not model failures. They were matching failures. The wrong architecture applied to the right problem. A team that chose an LLM when they needed an MLM. A product that deployed a dense model when MoE would have delivered the same quality at a third of the cost. A computer vision pipeline built on general-purpose models when SAM would have generalized across every domain they needed.
Understanding what each of these eight models actually does internally, not just what it is marketed to do, is the difference between building something that works and building something that almost works. And in production, almost working is the most expensive outcome of all.