The sun beats down on the bustling market in Ouagadougou, a familiar rhythm of life that hums with human ingenuity. Meanwhile, thousands of kilometers away, in the air-conditioned studios of Hollywood, a different kind of ingenuity is taking hold, one powered by algorithms and data: AI video generation. Companies like Runway ML are making waves, promising to revolutionize filmmaking. But for us, sitting under the Sahelian sky, the question isn't just about movie magic, it's about what we can learn from these complex systems to address our own pressing issues, particularly climate change. Forget the hype, this is what matters: understanding the mechanics.
When we talk about Runway ML, we are talking about a sophisticated piece of software that can create moving images from text, still images, or even other video clips. It is not a magic box, but a collection of interconnected AI models working in concert. Think of it like a skilled griot, not just reciting a story, but visualizing it, animating it, and bringing it to life based on your words. The big picture is this: Runway ML takes your creative prompt, whether it is a simple sentence or a complex storyboard, and translates it into a dynamic video sequence. It is about transforming abstract ideas into concrete visual narratives.
The Building Blocks: What Makes the Machine Move?
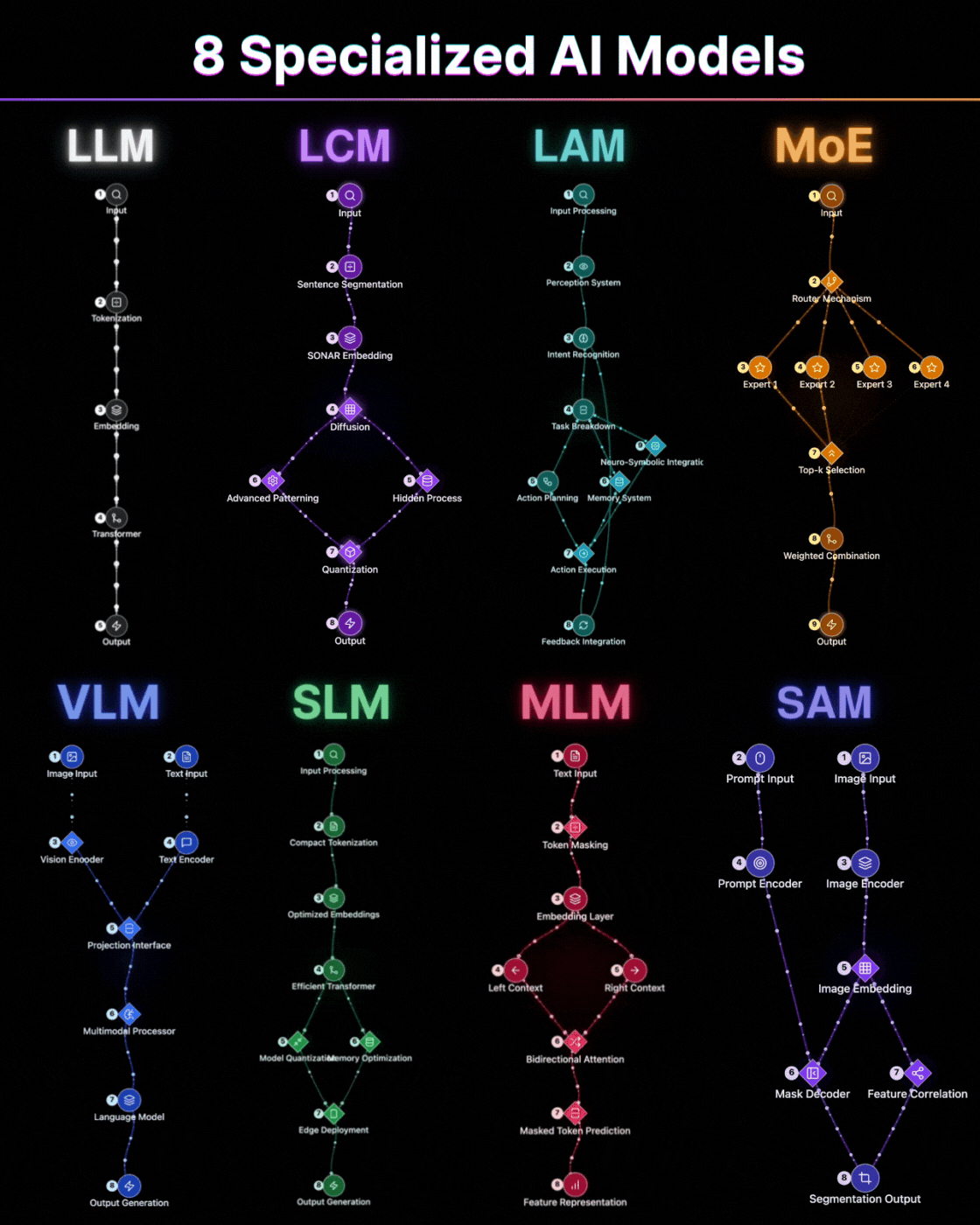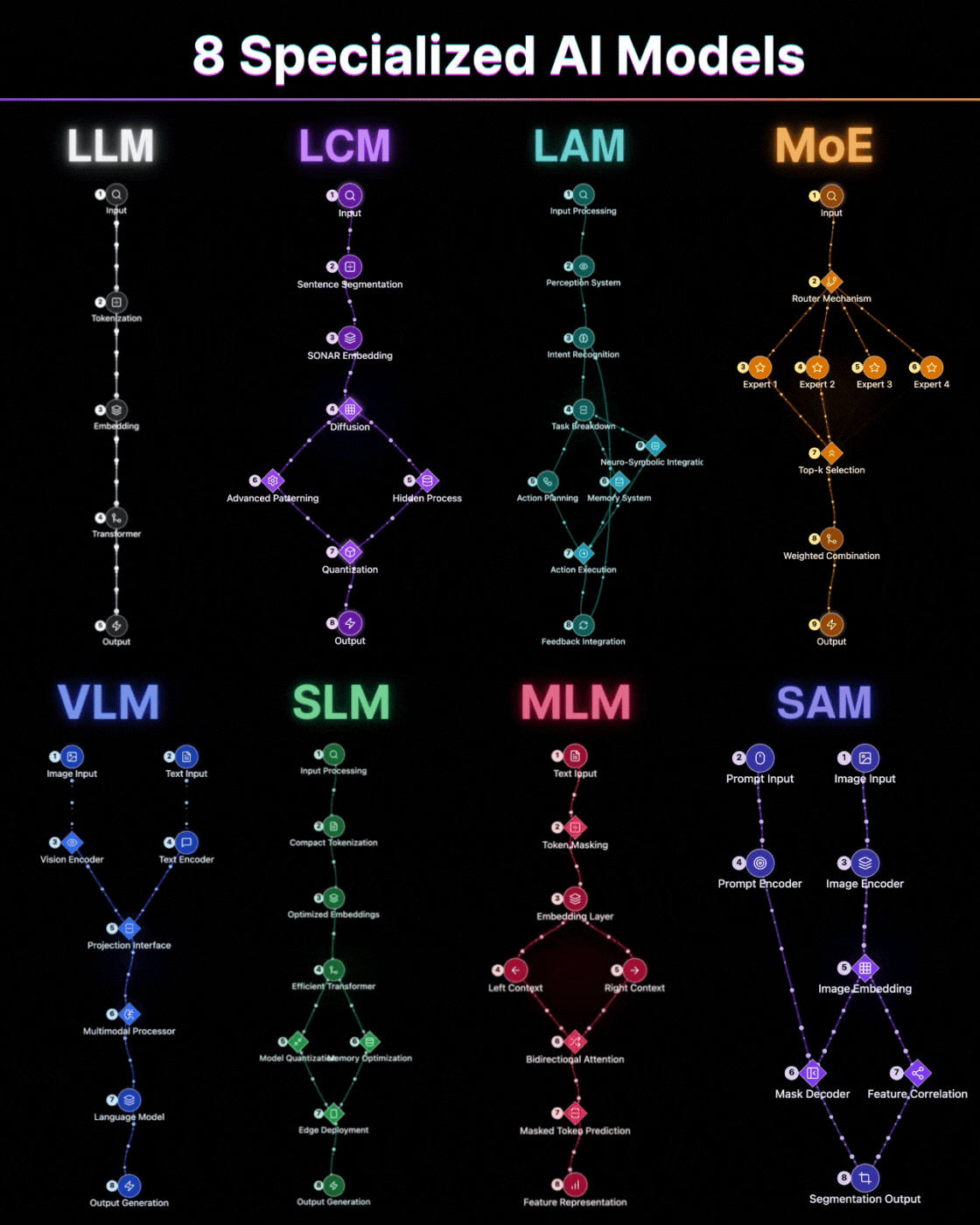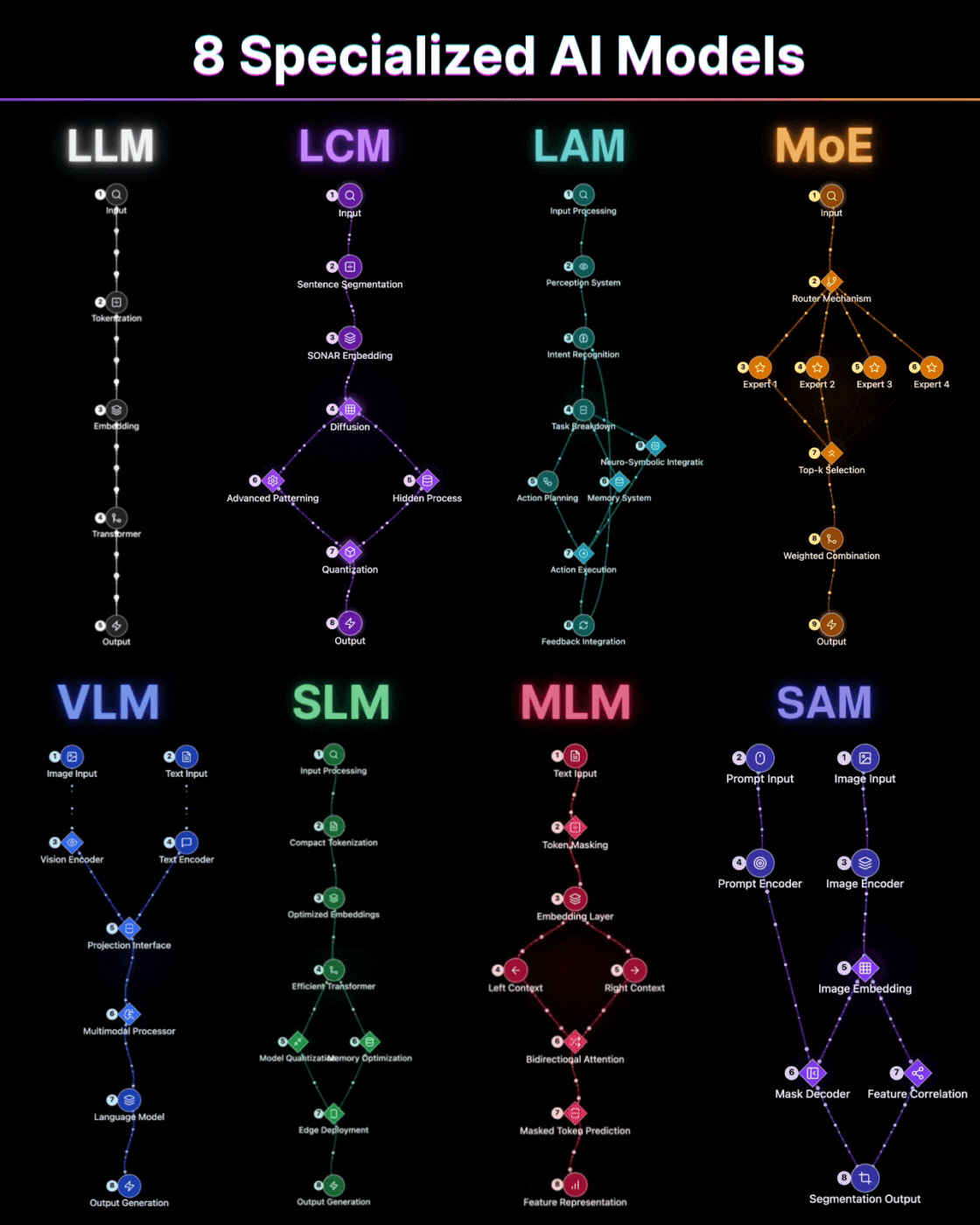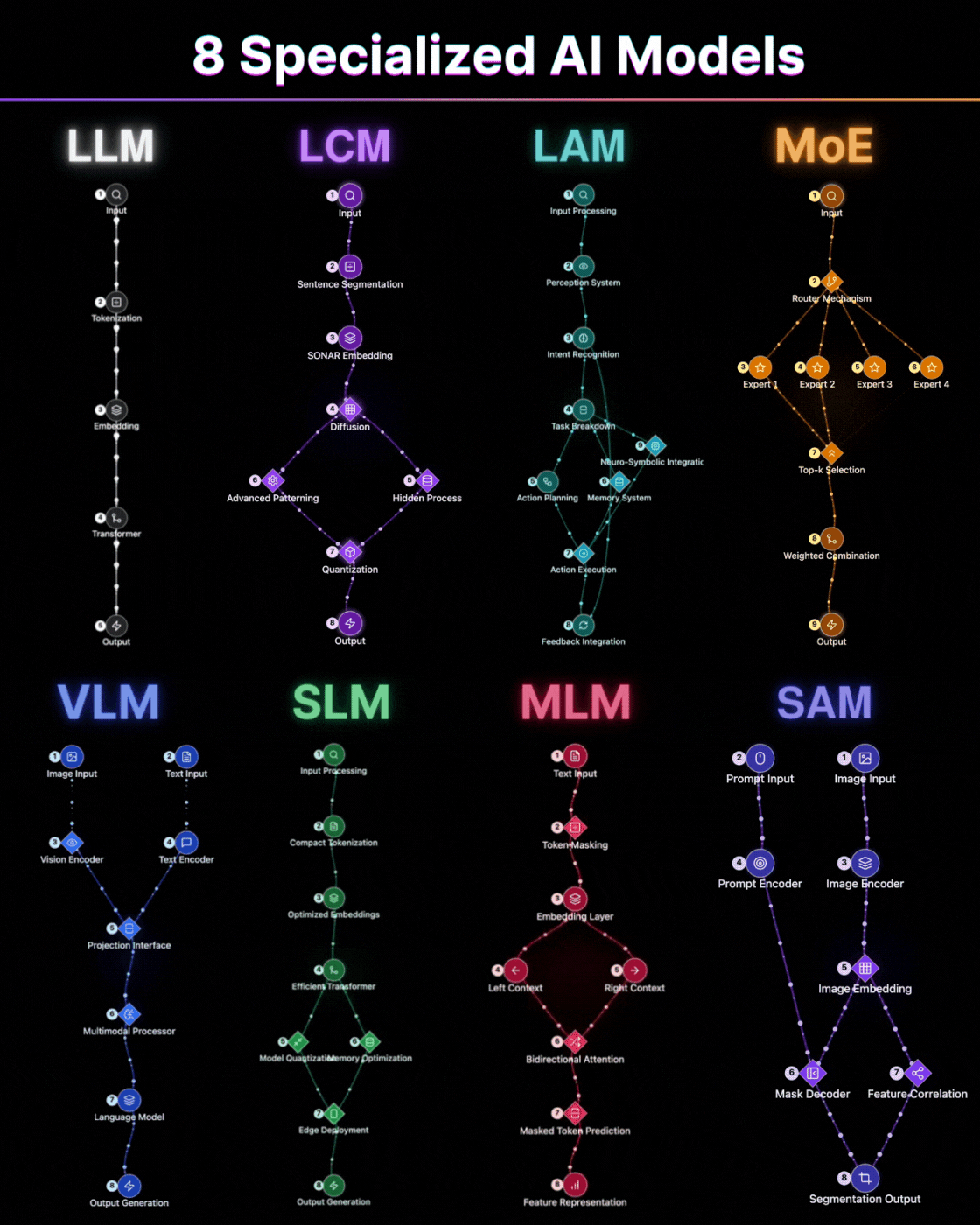
To understand how Runway ML works, we need to look at its core components, the digital bricks and mortar that build these moving pictures. There are primarily three types of AI models at play, each with a distinct role:
-
Text-to-Image Models (Diffusion Models): Before you can make a video, you often need to generate the individual frames, or at least understand what each frame should look like. This is where diffusion models come in. Imagine you have a blurry image, like a photograph taken in a dust storm. A diffusion model learns to 'denoise' that image, gradually adding detail until it is clear. In reverse, it can start from pure random noise and, guided by a text prompt, 'diffuse' information into it, creating a coherent image. These models are trained on massive datasets of images and their descriptions, learning the intricate relationships between words and visuals. When you type "a baobab tree under a full moon," the model knows what a baobab looks like, what a full moon implies, and how to combine them visually.
-
Image-to-Image or Image-to-Video Models: Once the AI has a good idea of what individual frames should look like, or if you provide it with an initial image, these models take over. Their job is to ensure consistency and introduce movement. They learn how objects move, how light changes, and how scenes transition. If you give it an image of a person standing, an image-to-video model can be prompted to make that person walk, or turn their head. It is like having a master puppeteer who understands the physics of movement and can animate static figures. This is where the magic of continuity happens, preventing your video from looking like a series of disconnected photographs.
-
Temporal Consistency Models: This is perhaps the most critical component for video generation. A video is not just a sequence of images; it is a story unfolding over time. Temporal consistency models ensure that objects, characters, and lighting remain consistent from one frame to the next. If a character is wearing a traditional faso dan fani in one frame, they should not suddenly be in a suit in the next, unless explicitly told to change. These models learn the 'flow' of time in video, predicting how elements should evolve smoothly. Without them, the video would flicker and jump, breaking the illusion.
Step by Step: From Idea to Moving Image
Let's walk through a simplified scenario, imagining we want to create a short video for a local NGO, showing the impact of climate change on a village in the Sahel, and then a solution.
Step 1: The Prompt and Initial Scene Setting.
You start by typing your creative brief into Runway ML. For example: "A parched landscape, cracked earth, a lone farmer looking distressed. Then, a scene of a community well, children fetching water, green shoots emerging." This text is fed into the text-to-image diffusion models. They begin to generate keyframes, like a storyboard artist sketching the most important moments.
Step 2: Generating Keyframes and Initial Visuals.
The diffusion models create high-resolution still images for your key moments: the parched land, the distressed farmer, the well, the children, the green shoots. These are not yet video frames, but detailed visual concepts. Think of it as the AI's first draft of the visual story.
Step 3: Introducing Motion and Transitions.
Now, the image-to-video models come into play. For the "parched landscape" image, you might add a prompt like "camera slowly pans across the cracked earth." For the farmer, "farmer slowly raises head, looks to the sky." The AI uses its understanding of movement to interpolate frames between these key images, creating smooth transitions and introducing subtle motion within each scene. It is like a traditional animator drawing the in-between frames, but at an incredible speed and scale.
Step 4: Ensuring Temporal Coherence.
As these individual motions are generated, the temporal consistency models are constantly checking. Does the light source remain consistent? Does the farmer's clothing stay the same? Does the well appear in the right place in subsequent frames? If there are discrepancies, the models adjust, ensuring that the entire sequence feels like a continuous, unbroken piece of footage. This is crucial for believability. According to The Verge, achieving perfect temporal consistency is one of the biggest challenges in AI video generation.
Step 5: Refinement and Iteration.
Once the initial video is generated, you, the user, can provide feedback. "Make the farmer look more hopeful in the second scene." "Change the color of the sky to reflect dawn." The AI then takes these new instructions and regenerates parts of the video, refining it until it matches your vision. This iterative process is what makes these tools so powerful for creators.
A Worked Example: Documenting the Sahel's Resilience
Let's take our climate change scenario. An NGO in Dori, Burkina Faso, wants to quickly produce a short film illustrating the effects of desertification and the success of a new water harvesting project. Traditional filmmaking would involve travel, equipment, crews, and weeks of shooting and editing. With Runway ML, they could:
-
Input: "Generate a 30-second video. First 15 seconds: extreme drought, dry riverbeds, wilting crops, a family struggling to find water. Next 15 seconds: a vibrant community with a newly installed solar-powered pump, children drinking clean water, irrigated fields, healthy crops, happy faces." They might upload a few reference photos of their actual project site or local people for stylistic guidance.
-
Processing: Runway ML's models would interpret these prompts. The diffusion models would create the visual elements, understanding 'drought' means cracked earth and brown tones, while 'vibrant community' means green, blue, and smiling faces. The image-to-video models would animate the water flowing, the crops growing, and people moving naturally. Temporal models would ensure the same family appears consistently, transitioning from distress to relief.
-
Output: Within minutes or hours, a draft video is ready. The NGO can then refine specific elements, perhaps asking for more emphasis on the solar panels, or a different angle on the children playing. This dramatically cuts down production time and cost.
“The ability to visualize complex scenarios, like the progression of desertification or the impact of a new agricultural technique, without needing extensive fieldwork for every single shot, is a game-changer for advocacy and education,” says Dr. Aminata Traoré, a climate scientist at the University of Ouagadougou. “It allows us to communicate urgent messages more effectively to a wider audience, including those who may not be able to visit affected regions.”
Why It Sometimes Fails: The Limits of the Machine
While impressive, Runway ML and similar systems are not perfect. Here's what actually happened sometimes: they can struggle with fine details, especially human hands or complex facial expressions, often producing uncanny or distorted results. Maintaining perfect consistency over very long video sequences is still a significant challenge. The AI might introduce subtle visual glitches, or objects might appear or disappear inexplicably. These are often referred to as 'artifacts.' The models are also only as good as the data they are trained on. If the training data lacks diverse representations, the generated videos might reflect biases, failing to accurately portray different cultures, environments, or complex social dynamics. This is a critical point for us in Africa, where datasets often underrepresent our realities.
“We’ve seen instances where AI models, trained predominantly on Western datasets, struggle to accurately depict traditional Burkinabé attire or local flora and fauna,” explains Monsieur Oumar Diallo, a filmmaker and cultural advocate from Bobo-Dioulasso. “The nuances are lost, and the output can feel generic or even misrepresentative. We need to ensure that the data feeding these systems is as diverse as the world we live in.” This highlights the ongoing need for diverse data collection and ethical considerations in AI development, a topic we often discuss at DataGlobal Hub, including how Burkina Faso is working to secure its digital future, as detailed in our previous piece on Burkina Faso's Data Sovereignty [blocked].
Where This is Heading: Beyond Hollywood's Glamour
The future of AI video generation is not just about blockbuster movies or viral marketing campaigns. For places like Burkina Faso, these technologies hold immense potential for education, climate communication, and even local content creation. Imagine farmers receiving instructional videos on new drought-resistant crops, personalized for their specific region and language, generated almost instantly. Or local artists using these tools to tell their stories, bypassing the need for expensive equipment and large production teams.
Companies like Google, NVIDIA, and Meta are pouring billions into improving these models, focusing on higher resolution, longer video generation, and better control over specific elements within a scene. The goal is to move from general text-to-video to highly controllable, editable, and stylistically consistent video generation. This means we could soon be able to specify not just 'a farmer,' but 'a farmer wearing a specific type of fabric, with a specific facial expression, against a backdrop of a specific village.'
“The trajectory is clear: more control, more realism, and greater accessibility,” states Dr. Fatoumata Konaté, a researcher in AI ethics at the Institut de Recherche en Sciences Appliquées et Technologies (irsat) in Ouagadougou. “The challenge for us is to ensure that these powerful tools are not just tools for the privileged few, but can be adapted and utilized by communities here, to address our unique challenges, from food security to renewable energy education. The reality on the ground demands practical applications, not just cinematic spectacle.”
The revolution in AI video generation, spearheaded by platforms like Runway ML, is a testament to human and algorithmic collaboration. While Hollywood revels in its new creative possibilities, the underlying technology offers a blueprint for how complex data processing and generative AI can be harnessed for practical, impactful applications far beyond entertainment. Here in Burkina Faso, as we face the realities of a changing climate, understanding these tools is not a luxury, but a necessity for building a more resilient future. The ability to visualize solutions, to educate, and to advocate with compelling, easily produced content, could be one of our most potent weapons against the challenges ahead. We must learn to wield it. For more on the broader AI landscape, TechCrunch offers frequent updates on industry developments.